클로드 오퍼스 4.6(Claude Opus 4.6) 혁 성능 분석, 요금제 가격 무료 팁

안녕하세요. IT 기술의 변화를 가장 빠르게 전달하고 분석하는 전문 블로거 엔돌슨 입니다. 오늘은 전 세계 AI 업계의 이목을 집중시키고 있는 Anthropic의 최신 역작, Claude Opus 4.6을 직접 사용해 보고 느낀 점과 주요 변화를 정리해 드리고자 합니다.

이번 업데이트는 단순히 성능이 조금 좋아진 수준을 넘어, 인공지능이 '지능형 에이전트'로서 어떻게 실무에 깊숙이 관여할 수 있는지를 명확히 보여주는 이정표와 같습니다. 특히 최근 GPT-5.3 Codex의 등장으로 더욱 치열해진 경쟁 상황에서 Claude가 가진 확실한 우위는 무엇인지, 그리고 사용자들이 느끼는 솔직한 단점은 무엇인지 가감 없이 다뤄보겠습니다.

1. 벤치마크 전쟁: GPT-5.3 Codex vs Claude Opus 4.6
AI 모델의 성능을 논할 때 벤치마크는 중요한 지표입니다. 최근 흥미로운 이슈는 GPT-5.3 Codex가 공개 직후 Terminal Bench에서 77.3%라는 압도적인 점수를 기록하며 기록을 갱신했다는 점입니다. 단 35분 만에 새로운 기록이 나오는 현상을 보며, 일각에서는 모델들이 특정 테스트에 과적합(Overfitting)되거나 마케팅을 위한 '벤치맥싱(Benchmaxxing)'에 치중하는 것이 아니냐는 우려를 표하기도 합니다.

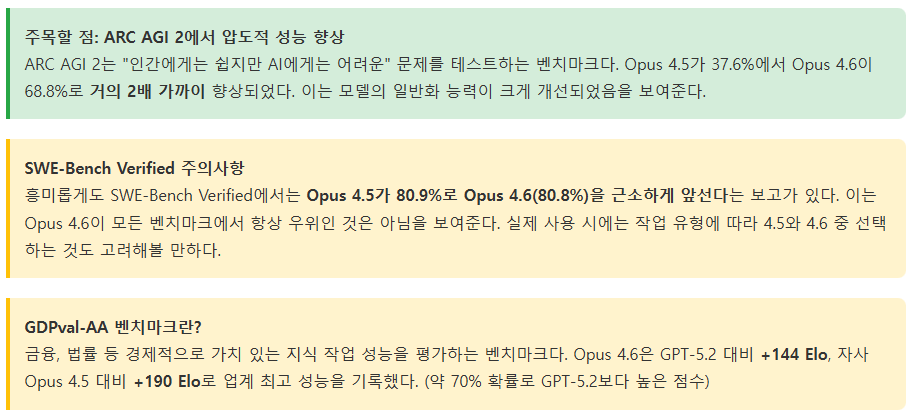
하지만 실무 개발자 입장에서 주목해야 할 지표는 따로 있습니다. 바로 SWE-bench입니다.
- Claude Opus 4.6: 80.8%
- GPT-5.3 Codex: 56.8% (초기 기록 기준)
단순한 코드 생성을 넘어 복잡한 소프트웨어 엔지니어링 문제를 해결하는 능력에서는 여전히 Claude가 전반적인 우세를 보이고 있습니다. 점수 10포인트의 차이는 실무에서 에러를 잡아내는 '질적 차이'로 직결됩니다.

2. 1M 토큰 컨텍스트와 '기억하는' 에이전트
실무자로서 가장 놀라웠던 부분은 1M(100만) 토큰 컨텍스트 윈도우 지원과 자동 메모리 기능입니다.
기존 모델들은 대화가 길어지면 이전 내용을 잊어버리는 'Context Rot' 현상이 고질적인 문제였습니다. 하지만 Opus 4.6은 Context Compaction(컨텍스트 압축) 기술을 통해 오래된 정보를 핵심 위주로 요약하여 유지합니다.
특히 Claude Code 업데이트에 포함된 "자동으로 기억을 기록하고 불러오는 기능"은 Google Antigravity의 Knowledge 아티팩트와 유사한 개념으로, 작업 흐름을 끊지 않고 이어갈 수 있게 해줍니다. 60일간 비활성 시 자동 정리되지만, 프로젝트가 진행되는 동안에는 마치 동료가 회의 내용을 기억하듯 맥락을 유지합니다.
3. "We build Claude with Claude": 도그푸딩의 승리
Anthropic은 이번 릴리스에서 "We build Claude with Claude"라는 문구를 강조했습니다. 즉, Claude 자체를 개발하는 데 Claude를 사용했다는 '도그푸딩(Dogfooding)' 전략입니다.
실제로 Claude Code에는 6,000개 이상의 오픈 이슈가 존재하고 계속 늘어나고 있지만, 이는 제품이 실패했다는 뜻이 아닙니다. 오히려 개발팀 스스로가 샌드박싱 환경(비록 아직 완벽하진 않지만)에서 치열하게 테스트하며 품질을 끌어올리고 있다는 증거입니다. React 앱이 터미널로 출력되는 독특한 구조 역시 이러한 보안과 효율성 고민의 산물로 보입니다.
4. 실무 투입 후기: 코딩에는 '신(God)', 일상 대화는 '글쎄'
4.1 에이전트 팀(Agent Teams)의 강력함
Claude Code에 추가된 Agent Teams 기능은 혁명적입니다. 하나의 명령을 내리면 여러 에이전트가 병렬로 협업하며 하위 작업을 수행하고, 블로커(Blocker)를 식별하여 보고합니다. 비록 여러 모델을 동시에 돌리는 비용(Token Cost)이 부담될 수 있지만, 숙련된 개발자를 고용하는 비용에 비하면 여전히 합리적입니다.
4.2 펠리컨 그림과 이미지 생성 능력
재미있는 테스트로 모델에게 '자전거를 타는 펠리컨'을 그려달라고 요청해 보았습니다.
- 결과: 펠리컨 자체의 묘사는 훌륭했으나, 자전거 프레임은 다소 삐뚤고 펠리컨의 두 다리가 같은 쪽에 있는 등 기하학적 오류가 있었습니다.
- 분석: 이는 모델이 이미지를 단순히 '검색'해서 보여주는 것이 아니라, 픽셀 단위로 '생성'하고 있음을 보여줍니다. 사람도 자전거 구조를 제대로 그리기 어려워하는 것처럼, 모델 역시 학습 데이터의 통계적 특성을 따라가며 실수를 범하는 모습이 오히려 인간적으로 느껴지기도 했습니다.
4.3 언어적 한계
코딩 능력은 타의 추종을 불허하지만, 비영어권 언어 지원은 여전히 아쉽습니다. 한국어나 체코어 등 영어 외 언어에서는 가끔 단어를 지어내거나 문맥이 어색한 경우가 발생합니다. 일상적인 정보 탐색이나 수다 용도라면 ChatGPT나 Gemini가 더 나은 선택일 수 있습니다.
5. 경제성 분석: 이 가격, 지속 가능할까?
Claude Opus 4.6의 API 가격은 입력 $5 / 출력 $25 (per 1M tokens)로 유지되었습니다. DeepSeek V3와 같은 오픈 모델들이 파격적인 가격($0.4/$1.2)을 제시하는 상황에서 Anthropic의 가격 정책은 다소 비싸 보일 수 있습니다.
하지만 이는 모델 생애주기 경제학으로 이해해야 합니다. DeepSeek는 추론 비용 최적화에 집중했지만, Anthropic은 막대한 R&D 및 훈련 비용(Sunk Cost)을 회수해야 하는 입장입니다. Dario Amodei CEO가 언급했듯, 모델은 수명 전체 기준으로 수익성을 따져야 합니다.
현재 에이전트형 코딩 붐은 $200/월 플랜 등이 보조하고 있는 구조일 가능성이 높으며, 향후 사용량이 폭증하면 가격 인상 가능성도 배제할 수 없습니다. 하지만 지금 당장은 "Worse is Better(적당한 것이 최고다)" 전략보다는, 코딩 도메인에서 압도적인 성능(Moat)을 구축하여 시장을 선점하려는 전략으로 보입니다.
6. 결론 및 혜택 정보
Claude Opus 4.6은 완벽하지 않습니다. 일상 대화 능력은 경쟁사에 비해 평범하고, 영어 이외의 언어 능력은 개선이 필요합니다. 하지만 "코딩과 복잡한 문제 해결"이라는 특정 도메인에서는 대체 불가능한 퍼포먼스를 보여줍니다.
GamsGo
프리미엄 구독을 더 저렴하게! GamsGo에서 ChatGPT 4.0, YouTube Premium, Netflix 등 다양한 서비스를 할인된 가격에 공유해보세요. 겜스고와 함께 비용 절약하고 최고의 혜택을 누리세요!
www.gamsgo.com
위의사이트를 통해 공유계정으로도 할인된 가격으로 클로드 오퍼스를 구매할 수 있습니다. 참고하세요.
[Tip] 프로모션 정보 현재 Anthropic에서는 Opus 4.6 출시를 기념하고 모델 사용을 독려하기 위해, 사용량 페이지에서 $50의 추가 크레딧을 제공하고 있습니다. 토큰 사용량이 많은 에이전트 기능을 체험해 보기에 좋은 기회이니 놓치지 마시기 바랍니다.
더 복잡하고 더 거대한 작업을 수행해야 하는 개발자라면, 지금이 바로 Claude Opus 4.6을 도입해 볼 적기입니다.